Appearance
16.3.3 重要检验
数理统计学的一个根本问题就是从样本中推断关于总体的结论. 有两类最重要的问题如下.
(1) 分布类型已知,欲估计其参数. 分布的特征通常可由参数
(2) 关于参数的假设已知, 欲检验其是否正确. 最常出现的问题是:
a) 期望值是否等于一个已知数?
b) 两个总体的期望是否相等?
c) 能否用参数为
正态分布在观察和测量中极其重要, 下面讨论对正态分布的拟合优度检验. 其基本思想也适用于其他分布.
16.3.3.1 对正态分布的拟合优度检验
在数理统计学中有不同的检验方法, 用于判断样本数据是否来自于正态分布. 此处讨论基于正态概率纸的图形检验和基于
1. 使用概率纸进行拟合优度检验
a) 概率纸的原理 在直角坐标系中,
若随机变量
即
成立,故
b) 概率纸的应用 对于样本数据, 把根据 (16.125) 计算的累计相对频率作为点的纵坐标, 组上界作为横坐标, 并把对应点描绘到概率纸上. 若这些点大致落在一条直线上 (偏差很小), 则随机变量可视为正态随机变量 (图 16.14).
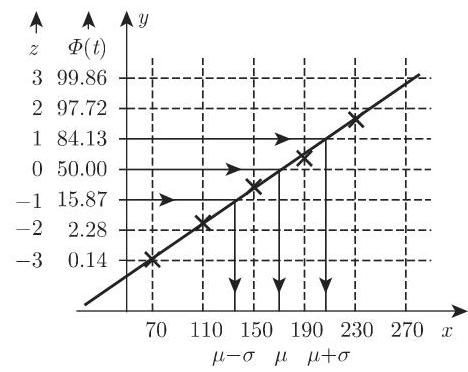
正如从图 16.14 中所看到的, 表 16.3 中的数据对应正态分布. 进一步可得到
注 如果关于
2.
欲检验随机变量
其中,
一定成立,其中
近似服从
如果随机变量
若确定了显著性水平
成立,则接受样本来自于正态分布的假设. 该检验也称为
下述
表
70 | -2.90 | 0.0019 | 0.0019 | 0.00005 | ||
90 | -2.35 | 0.0094 | 0.0075 | |||
110 | -1.81 | 0.0351 | 0.0257 | |||
130 | -1.26 | 0.1038 | 0.0687 | |||
150 | -0.72 | 0.2358 | 0.1320 | 16.5000 | 0.1635 | |
170 | 22 | -0.17 | 0.4325 | 0.1967 | 24.5875 | 0.2723 |
190 | 30 | 0.37 | 0.6443 | 0.2118 | 26.4750 | 0.4693 |
210 | 27 | 0.92 | 0.8212 | 0.1769 | 22.1125 | 1.0803 |
230 | 9 | 1.46 | 0.9279 | 0.1067 | 13.3375 | 1.4106 |
250 | 2.01 | 0.9778 | 0.0499 | 0.0526 | ||
270 | 2.55 | 0.9946 | 0.0168 | |||
由最后一列可知
16.3.3.2 样本均值的分布
令
1. 样本均值的置信概率
如果
成立. 因此,当样本容量
表 16.5 列出了
1 | 38.29% |
4 | 68.27% |
16 | 95.45% |
25 | 98.76% |
49 | 99.96% |
2. 总体服从任意分布时的样本均值分布
若总体服从期望为
16.3.3.3 均值的置信限
1. 方差
如果
可生成近似服从标准正态分布的随机变量
若给定显著性水平
成立,则
成立. (16.137) 中数值
注 若样本容量足够大,则
2. 方差
若总体近似服从正态分布,且方差
该变量服从自由度为
由 (16.139) 可得
数值
一组样本包含下述 6 个测量数据:0.842,0.846,0.835,0.839,0.843,0.838,可得到
若给定显著性水平
(1)
(2)
16.3.3.4 方差的置信区间
若随机变量
服从自由度为
于是,由
根据 (16.141) 可推出,当显著性水平为
对于小样本,(16.144) 所给出的
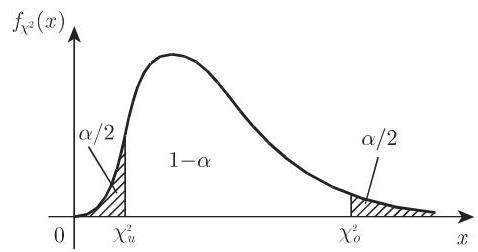
16.3.3.5 假设检验的结构
统计学上的假设检验具有下述结构:
(1) 首先,要对样本来自于具有某种特定性质的总体作出假设
(2) 以假设
(3) 计算样本函数值. 若函数值落在给定区间
- 给定显著性水平
,检验假设 .
根据第 1093 页 16.3.3.3,随机变量
成立, 则拒绝该假设. 此时可称存在显著性差异, 对假设检验的深入探讨参见 [16.24].